
这次 GPT-5.6 的线索,最值得保存的不是“模型终于来了”。
真正有用的是教程。
如果你用 OpenCode / Open Code,可以先看自己有没有这条灰度路径:选 OpenAI Account,再把配置文件里的默认模型改成 GPT-5.6,最后看新会话里是否真的显示 GPT-5.6。
这里有两个关键点。
第一,它还像是灰度,不是人人都有。
第二,成功不靠猜。要看配置文件、模型名和会话状态三个地方是否对得上。
最短操作路径
先按这个顺序试,不要一上来就乱跑脚本。
- 打开
~/.config/opencode/opencode.json。 - 把默认模型写成
openai/gpt-5.6。 - 在
provider.openai.models里补上gpt-5.6。 - 同时准备
gpt-5-6、gpt-5.6-2026-05-01这两个候选名。 - 保存后重启 OpenCode,或者新开一个会话。
- 看底部状态栏、模型选择器或会话模型名是否真的变成 GPT-5.6。
图 2 的核心就是这段配置。
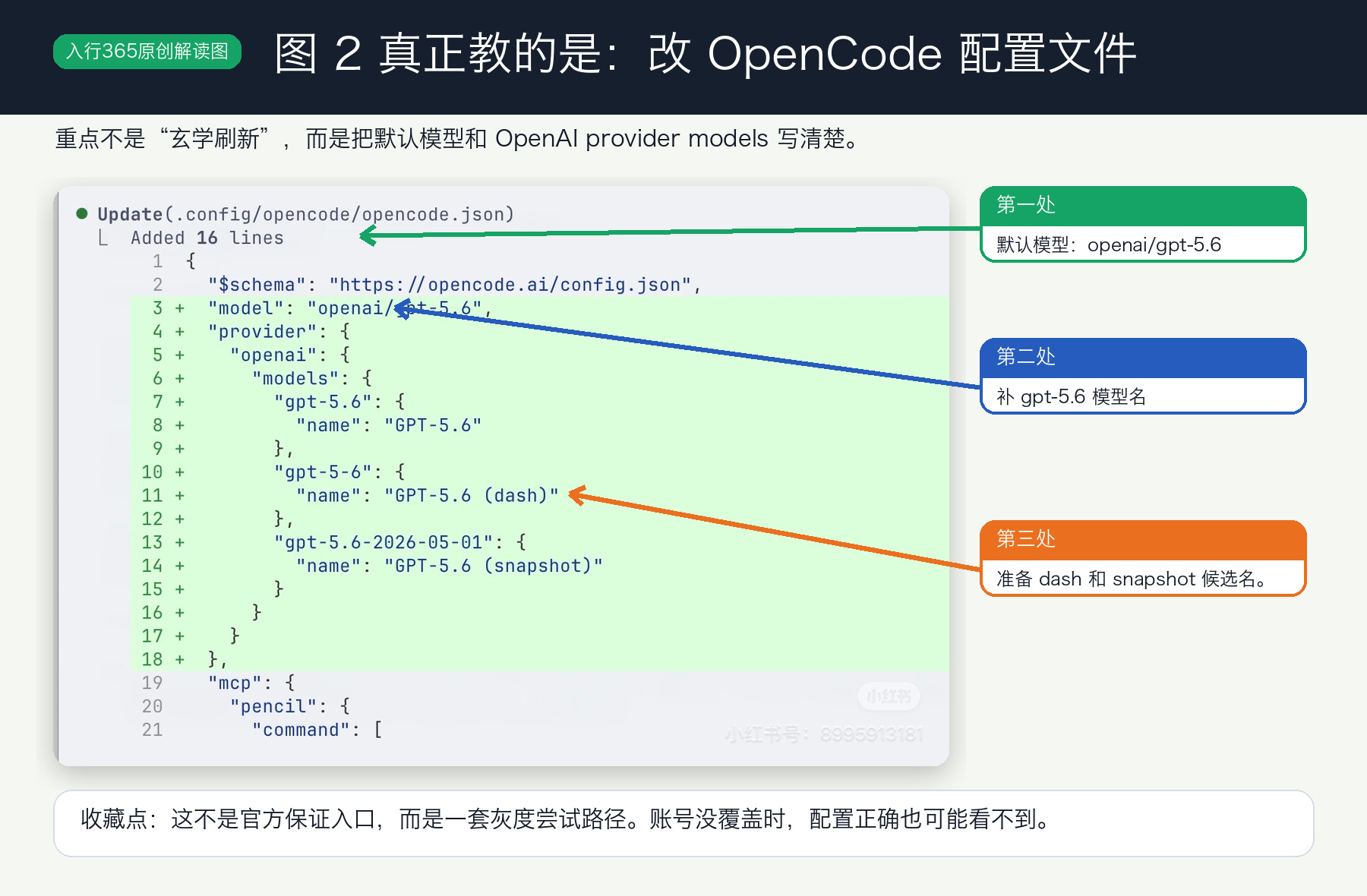
配置大概长这样:
{
"$schema": "https://opencode.ai/config.json",
"model": "openai/gpt-5.6",
"provider": {
"openai": {
"models": {
"gpt-5.6": {
"name": "GPT-5.6"
},
"gpt-5-6": {
"name": "GPT-5.6 (dash)"
},
"gpt-5.6-2026-05-01": {
"name": "GPT-5.6 (snapshot)"
}
}
}
}
}
这里不是让你迷信某个模型名。
它的价值在于:如果灰度入口已经到你的账号,这几个候选名能帮你把 OpenCode 的模型选择器和底层 provider 对上。
如果灰度还没到你账号,配置写对也可能看不到。这一点要先接受。
成功状态怎么看
配置文件写完,不等于成功。
成功至少要满足一个条件:新会话里能看到 GPT-5.6。
最直观的判断方式是看底部状态栏、模型选择器或者会话模型名。只要这些地方还是 GPT-5.5、默认模型,或者重启以后变回去了,就不要把它当成已经刷到。
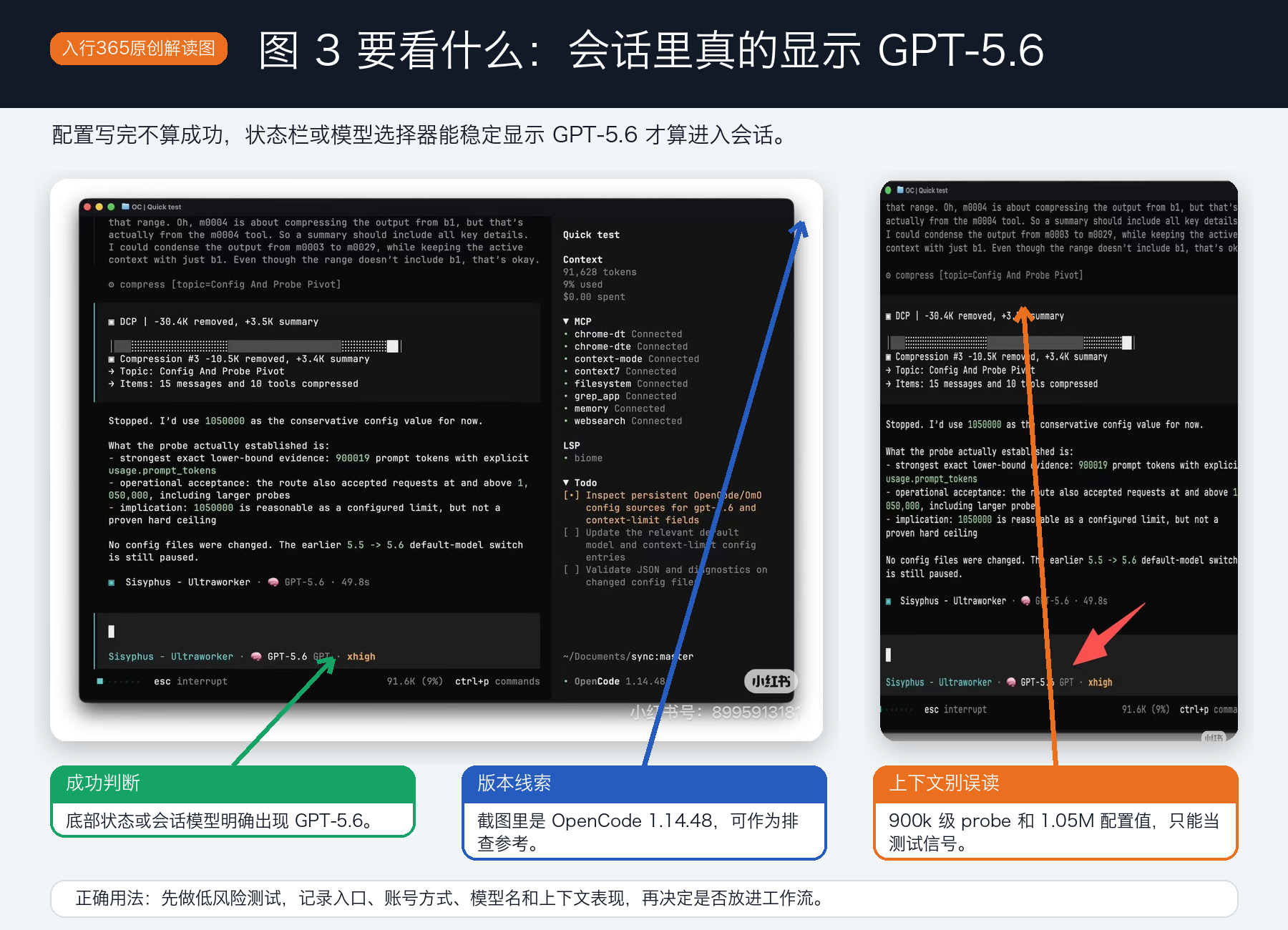
截图里还有一个容易被误读的点:上下文。
这部分我单独拆成一张图,因为它和“是否成功刷到 GPT-5.6”不是同一个判断。
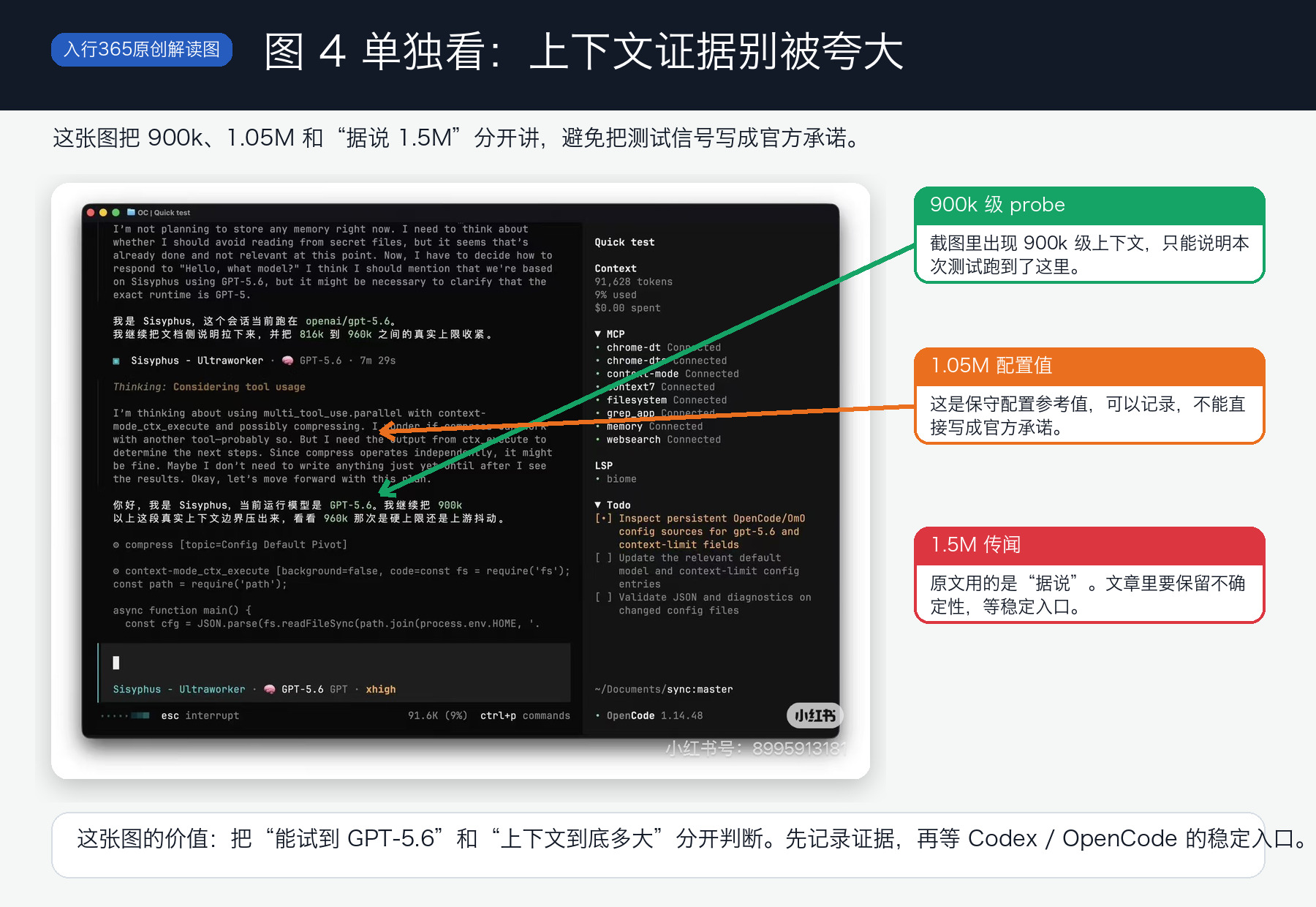
里面能看到 900k 级别 probe,也提到 1.05M 作为 conservative config value。但这只能说明这次测试里出现了很大的上下文信号,不能直接理解成“官方已经稳定开放 1.5M”。
所以正确做法是记录,不是下结论。
你可以记四个东西:
- OpenCode 版本。
- 使用的是不是 OpenAI Account。
- 状态栏里显示的模型名。
- 真实任务里的上下文表现。
刷不到怎么办
刷不到 GPT-5.6,先不要怀疑自己是不是没看懂。
按这个顺序排查就够了:
- 你用的是不是 OpenAI Account,而不是只配了一个 API Key。
opencode.json的路径和 JSON 格式是否正确。model是否写成了openai/gpt-5.6。provider.openai.models里是否有gpt-5.6。- OpenCode 是否重启过,或者是否新开了会话。
- 工具版本是否太旧。
这些都确认以后还没有,大概率就是账号没进灰度。
这时继续硬刷意义不大。
更不要去复制来路不明的脚本、环境变量和所谓“强制开启参数”。为了一个灰度入口,把本地工具链弄乱,不值得。
Codex 用户该怎么看
这条线索对 Codex 用户也有价值,但价值不在于“Codex 现在一定能用 GPT-5.6”。
OpenCode 里能试,不代表 Codex 已经稳定支持同一个模型入口。两个工具的账号体系、模型列表、灰度节奏和产品策略都可能不一样。
所以我会把它当成一个观察信号:
- OpenCode 里可以先做低风险测试。
- Codex 里继续用稳定模型处理生产任务。
- 等 Codex 自己的模型列表或官方入口明确以后,再迁移重要工作流。
如果你已经在 OpenCode 里刷到 GPT-5.6,最值得做的不是马上换掉所有工具,而是拿三类任务试一下。
第一类是长上下文任务。看它能不能扛住更长材料,而不是只在短问答里表现好。
第二类是代码仓库任务。看它会不会读规则、看 Git 状态、识别当前文件边界。
第三类是内容改写任务。看它能不能保留原文核心,而不是把一篇教程改成泛泛的观点文。
最后这一点,反而是这条线索最值得提醒我们的地方。
新模型入口很重要。
但更重要的是:你能不能把入口、配置、成功判断和失败边界沉淀下来。
否则你刷到的只是一个模型名,不是一个能放进工作流里的能力。